Highlighting Proofread Results
This time we’re going to display results of proofreading. We will highlight issues in a text panel.
The source code for this post is available in the 06-highlighting-proofread-results folder in the elm-proofreading repository.
Highlighting Text with Problems
I want to highlight problem places in a text. As an input, we’ve got a text and list of comments. Each comment contains an offset, which is a start index for a problem in a text, and a length of a problem text.
Let’s consider the following text. There are two misspelled words we need to highlight:
text—“I like Wensdeys and Thusrdays.”comments— [ { message: “Possible spelling mistake found”, offset: 7, length: 8, }, { message: “Possible spelling mistake found”, offset: 20, length: 9, } ]
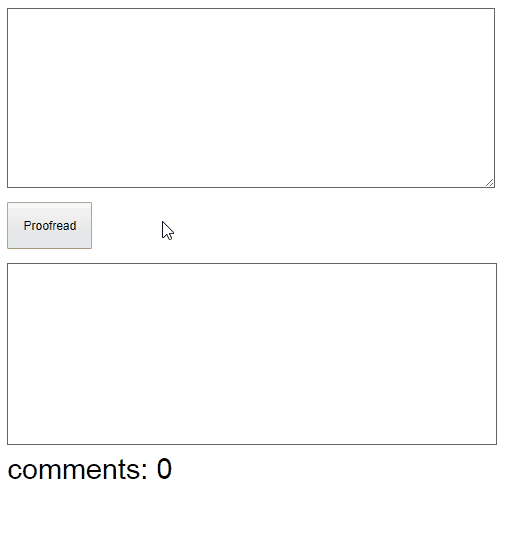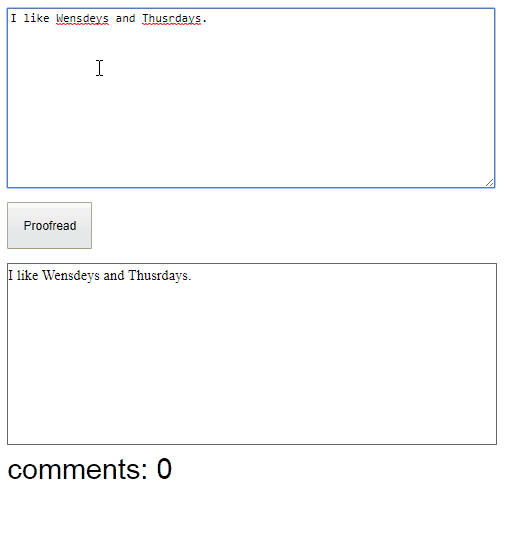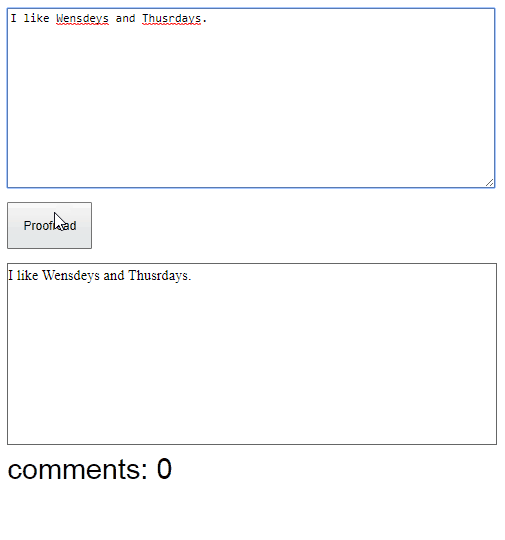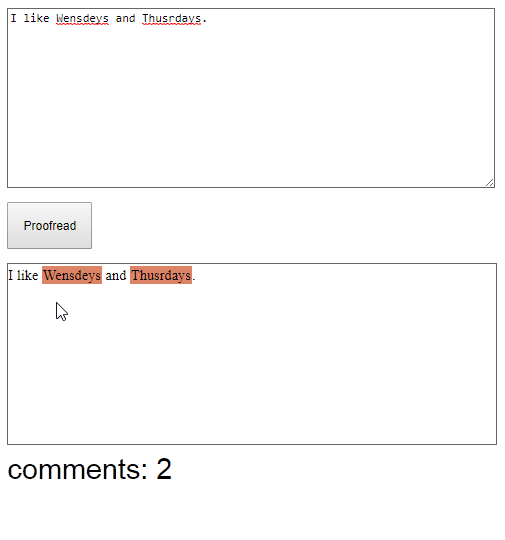
And here’s the output that I’d like to have:
To get this view we’d need the following HTML markup:
<div class="proofread-panel">
<span class="text">I like </span>
<span class="comment">Wensdeys</span>
<span class="text"> and </span>
<span class="comment">Thusrdays</span>
<span class="text">.</span>
</div>Everything is wrapped into the <div> tag with proofread-panel CSS class that draws a border. Each comment is wrapped in a <span> tag with the comment CSS class applied to it. All the text parts between comments are wrapped in <span> tags with text CSS class.
The viewCommentsPanel function does exactly that—it recieves a text string and a list of comments, and returns Elm HTML elements that form a needed markup.
viewCommentsPanel : String -> List Message -> Html Msg
viewCommentsPanel reviewedText comments =
div [ class "proofread-panel" ]
(viewHighlightedText reviewedText 0 comments)The viewCommentsPanel function declares a div element and calls the viewHighlightedText function to get a list of child elements for this div.
The viewHighlightedText is where all the magic happens. It gets a string with a text, a list of comments, and an index. The index stores the last part of a text that has already been processed. Let’s look at the function code before digging on:
viewHighlightedText : String -> Int -> List Message -> List (Html Msg)
viewHighlightedText reviewedText lastProcessedIndex comments =
case comments of
comment :: xComments ->
let
leftText =
String.slice lastProcessedIndex comment.offset reviewedText
commentEndIndex =
comment.offset + comment.length
commentText =
String.slice comment.offset commentEndIndex reviewedText
in
span [ class "text" ] [ text leftText ]
:: span [ class "comment" ] [ text commentText ]
:: viewHighlightedText reviewedText commentEndIndex xComments
[] ->
let
restOfText =
String.slice lastProcessedIndex (String.length reviewedText) reviewedText
in
span [ class "text" ] [ text restOfText ] :: []First of all, we check the comments list. If it’s not empty, we destructing a list to get next comment and a rest of comments (xComments List). Then we get a text between the last processed index and a beginning of a comment (i.e. leftText), and a text that we’ve got a comment for (i.e. commentText). After that, we construct a list that contains a span with a leftText, a span with a commentText, and the result returned by the recursive call of the viewHighlightedText function. For the recursive call, we pass a text, a list with a rest of comments, and an index of the letter right after the processed comment.
In case if the viewHighlightedText with an empty list of comments, we return a span with a rest of text.
Here is how it will work for our text
I like Wensdeys and Thusrdays.
Step 1
- Input (text, lastProcessedIndex, and two comments):
- I like Wensdeys and Thusrdays.
- 0
- [ { message: “Possible spelling mistake found”, offset: 7, length: 8, }, { message: “Possible spelling mistake found”, offset: 20, length: 9, } ]
- Work
- take the first comment from the list (with
offsetequal to 7 andlengthequal to 8); leftTextwould be “I like “;commentTextwould be “Wensdeys”;commentEndIndexwould be 15 (i.e. right after the “Wensdeys”);- create a
spanforleftText“I like “; - create a
spanforcommentText“Wensdeys”; - call the
viewHighlightedTextfunction recursively passing the initial text, the rest of comments (i.e. a list with the second comment), and a lastProcessedIndex of 15.
- take the first comment from the list (with
Step 2
- Input (text, lastProcessedIndex, and a list with one comment):
- I like Wensdeys and Thusrdays.
- 15
- [ { message: “Possible spelling mistake found”, offset: 20, length: 9, } ]
- Work
- take the first comment from the list with (
offsetequal to 20 andlengthequal to 9); leftTextwould be “ and “;commentTextwould be “Thusrdays”;commentEndIndexwould be 29 (i.e. right after the “Thusrdays”);- create a
spanforleftText“ and “; - create a
spanforcommentText“Thusrdays”; - call the
viewHighlightedTextfunction recursively passing the same text, the rest of comments (i.e. an empty list), and a lastProcessedIndex of 29.
- take the first comment from the list with (
Step 3
- Input (text, lastProcessedIndex, and an empty list of comments):
- I like Wensdeys and Thusrdays.
- 29
- [ ]
- Work
- the list of comments is empty;
- take
restOfTexttext from thelastProcessedIndextill the end of text; - create a
spanforrestofText, which is just period “.”; - return a span joined with an empty list. Note: we cannot return just
spanbecause the function should return a list, and not a single element. So we join it with an empty list.
- Result
- the function returns a list with five
<span>elements.
- the function returns a list with five
Now, all we need is to implement CSS rules for text and comment classes. In our case, I just set a background color for commented text to make it visible.
In the last post, we will allow selecting comments and will show a description for them.
Stay tuned!